Một nghiên cứu mới cho thấy các nỗ lực phát hiện thuốc dựa trên thư viện hóa học được mã hóa bằng mã vạch DNA (DNA-encoded chemical libraries) đang vô tình bỏ qua nhiều ứng viên thuốc tiềm năng.
Trong các thư viện dạng này, mỗi phân tử được gắn với tag định danh là một chuỗi DNA duy nhất hoạt động như một “mã vạch”. Các thư viện này đã mang lại lợi ích rất lớn trong giai đoạn đầu của quá trình phát triển thuốc, cho phép các nhà khoa học sàng lọc hàng triệu, thậm chí hàng tỷ hợp chất cùng lúc. Những dữ liệu thu thập được từ thư viện thường được sử dụng để huấn luyện các thuật toán máy học (machine learning algorithm) nhằm xác định các hợp chất có tiềm năng trở thành thuốc.
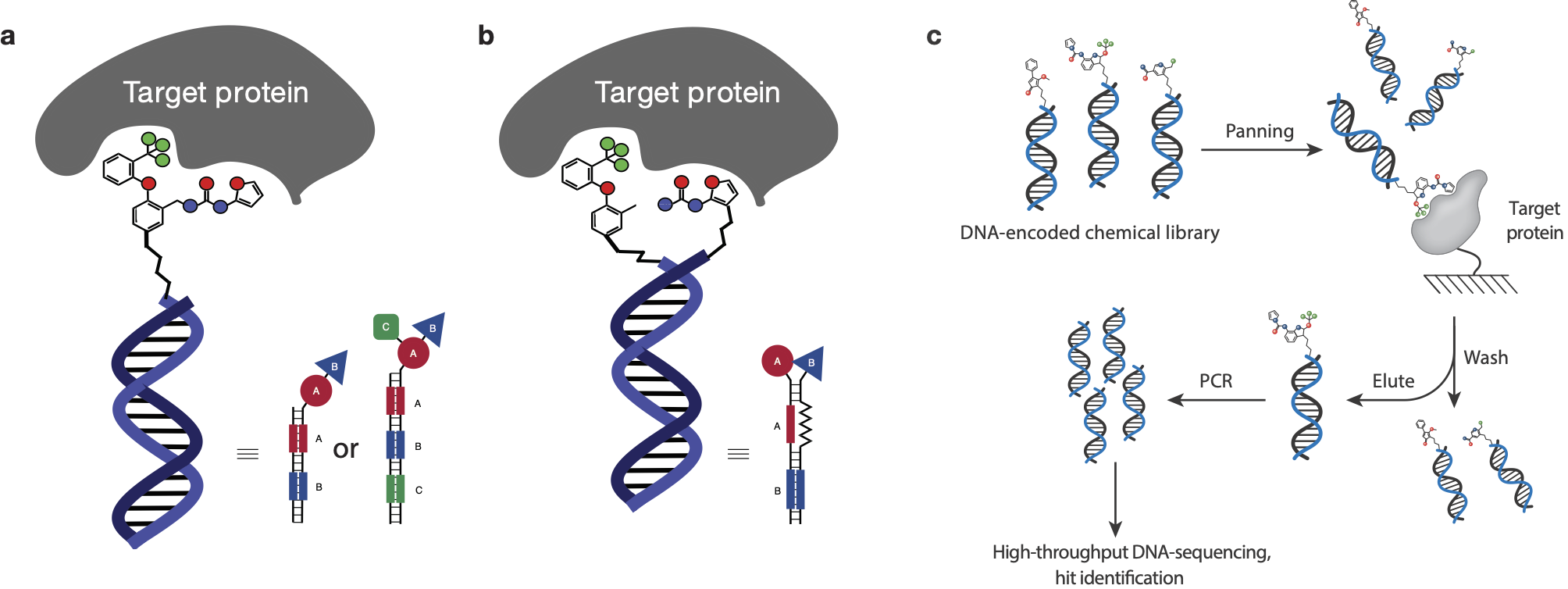
Minh họa thư viện hóa học mã hóa bằng mã vạch DNA và quá trình sàng lọc hợp chất từ thư viện
Muốn hiểu rõ hơn về độ tin cậy của dữ liệu thu được từ thư viện hóa học mã hóa bằng mã vạch DNA, GS Raphael Franzini (Đại học Utah, Mỹ) và cộng sự đã nghiên cứu một thư viện gồm hơn 58.000 hợp chất được thiết kế để tác động lên các enzyme liên quan đến ung thư và quá trình sửa chữa DNA.
Khi nhóm nghiên cứu tổng hợp và thử nghiệm 33 hợp chất đã bị loại bỏ trong sàng lọc, họ phát hiện ra rằng những hợp chất này hoạt động hiệu quả ngang với các hợp chất được xem là có triển vọng. Đáng chú ý, nhiều hợp chất gần như bị bỏ sót hoàn toàn dù có cấu trúc tương tự với olaparib, một loại thuốc trị ung thư đã được phê duyệt.

Cấu trúc olaparib
Chúng tôi phát hiện rằng dữ liệu từ thư viện mã hóa DNA thường gán nhãn sai những phân tử tốt thành phân tử xấu,” Franzini cho biết.
Vấn đề dường như bắt nguồn từ chính các mã vạch DNA. Khi nhóm nghiên cứu so sánh các hợp chất có gắn mã DNA với các hợp chất không gắn, họ nhận thấy rằng mã vạch DNA có thể gây sai lệch trong nhận định về mức độ và phạm vi hoạt động của các phân tử. Điều này được thể hiện rõ khi các phân tử được thử nghiệm trên mục tiêu khác với mục tiêu thiết kế ban đầu.
Nghiên cứu góp phần cảnh báo rõ ràng về tác động tiêu cực của các trường hợp âm tính giả trong dữ liệu sàng lọc. Những sai lệch này có thể gây ảnh hưởng nghiêm trọng đến độ chính xác của các thuật toán máy học, vốn ngày càng được ứng dụng rộng rãi trong lĩnh vực phát hiện và phát triển thuốc.

Minh họa hệ thống máy học
Franzini và cộng sự cũng cho thấy rằng, ngay cả khi các mô hình máy học dường như hoạt động tốt, chúng thực chất chỉ đang nhận diện các mảnh cấu trúc lặp lại, chứ không học được khả năng dự đoán thực sự.
Điều này cho thấy rằng các thuật toán máy học hiện nay trong khám phá thuốc có thể cần được thay đổi cơ bản để xử lý được các thiên lệch vốn có trong dữ liệu sàng lọc.
Nguồn: Chemistry World
Người dịch và tổng hợp: ThS. Ngô Đăng Trường Hải